Building AUR Packages with Forgejo Actions and Renovate 2026-06-19, 23:00 en Arch Linux AUR Forgejo Software Packaging Continuous Delivery
Unified Kernel Images and Secure Boot using Arch Linux 2025-09-17, 00:00 en Linux Secure Boot Boot Automation
Migration of Etherpad Lite from MariaDB to PostgreSQL 2025-08-30, 00:00 en Migration Etherpad Database PostgreSQL
Talk: «Propagation of OpenPGP Keys using WKD, WKS and DANE» 2024-06-29, 00:00 de en Talks Vorträge OpenPGP WKD WKS DANE DNSSEC E2EE
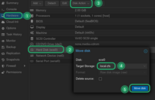
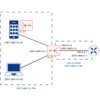
Issue Let's Encrypt Certificates with TSIG Zone Updates against Knot 2024-05-13, 21:49 en Knot TSIG Let's Encrypt